Laboratorium 10¶
Uczenie i wybór modelu¶
Dzisiejszym laboratorium kontynuujemy budowanie spójnego potoku masowego przetwarzania danych. Ostatnio zaimplementowaliśmy mechanizm wektoryzacji wraz z możliwością eksploracji danych.
Dzisiaj zajmiemy się przygotowaniem uczenia oraz wyboru modeli uczenia maszynowego.
Diagram planowanego systemu wygląda następująco:
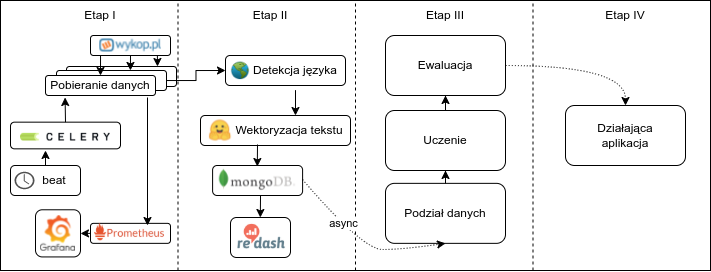
Aktualnie będziemy implementować zakres Etapu III
Zadanie 10.0: przygotowanie środowiska (0 pkt)¶
Skopiuj potrzebny kod źródłowy z repozytorium zawierającego ostatnie zadanie (Lab 9), będziesz go używać jako bazy pod rozwiązanie poniższych zadań. Lista przygotowana jest pod wykonanie za pomocą pySpark (Scala Spark będzie podobna jeżeli chodzi o nazewnictwo klas), listę można zrealizować zarówno w Pythonie jak i JVM (Scala, Java, Kotlin) z wykorzystaniem Sparka bądź Flinka.
Zadanie 10.1: przygotowanie danych (1 pkt)¶
Przygotuj kod który pobierze dane z twojej bazy a następnie zapisze jes w formacie CSV (bądź innym który będziesz w stanie wczytać w kolejnych krokach)
Zadanie 10.2: ładowanie i podział danych (2 pkt)¶
Wczytaj dane za pomocą pySpark oraz dokonaj ich podziału
pySparka wykorzystujemy w trybie local, zadbaj o odpowiednią konfigurację
Zadanie 10.3: zbuduj potok przetważania (8 pkt + 2pkt[za dodatkowe atrybuty])¶
Zbuduj potok przetwarzania który odpowiedni zmodyfikuje twój DataFrame do postaci akceptowanej przez pySpark ML, oraz nauczy model. Umożliwij predykcję dla dowolnego tekstu oraz przeprowadź predykcję na danych testowych. Dokonaj ewaluacji w oparciu o dane testowe. Wykorzystaj miary ewaluacji dla modeli regresji
dane musimy sprowadzić do postaci tabeli o kolumnach “features” i “label”
na podstawie cech chcemy przewidywać ilość plusów
wykorzystujemy LinearRegression
możemy wprost wykorzystać zwektoryzowany tekst
możemy zwektoryzować dodatkowe cechy za pomocą odpowiednich narzędzi [1, 2, 3] (dodatkowe punkty za dodatkowe atrybuty)
dodatkowo możemy rozbudować zwektroryzowany tekst o dodatkowe zwektoryzowane cechy
Zadanie 10.4: dobór parametrów (8 pkt)¶
Stwórz kolejny potok przetwarząnia który dobierze parametry modelu regresji za pomocą podziału na zbiór uczący i walidacyjny
piepline może być traktowany jako estymator, przez co może być przekazany do
TrainValidationSplitdokonaj ewaluacji najlepszego modelu na danych testowych
dokonaj ewaluacji modelu na danych wprowadzanych “z palca” (tekst jako zmienna w kodzie)