Laboratorium 8¶
Implementacja rozproszonego mechanizmu pozyskiwania danych¶
Niniejszym laboratorium rozpoczynamy część zajęć poświęconą budowaniu spójnego potoku masowego przetwarzania danych. Na kolejnych zajęciach będziemy rozbudowywali stworzony dziś moduł i dokładali do niego kolejne elementy.
Diagram planowanego systemu wygląda następująco:
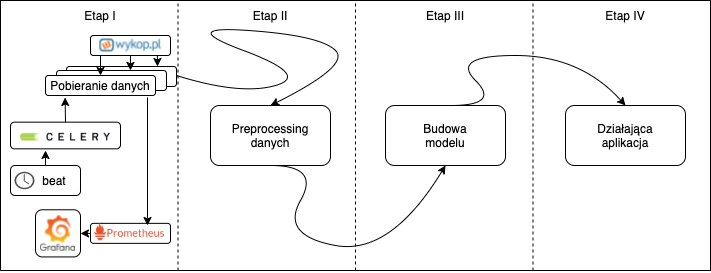
Aktualnie będziemy implementować zakres Etapu I
Zadanie 8.1: pozyskiwanie danych (5 pkt)¶
Używając zdobytej dotychczas wiedzy, stwórz task Celery, którego zadaniem będzie pobieranie aktualnych wpisów z mikrobloga serwisu Wykop.pl
Możesz:
a) uzyskać dostęp do API: dokumentacja
b) stworzyć mechanizm scrapowania
Pozyskaj dane z najnowszych wpisów lub wpisów dotyczących konkretnego tagu - wybór tagu wedle uznania
Pozyskaj dane w formie pojedynczych wpisów. Zadbaj o zebranie:
treści wpisu
daty utworzenia
nazwy autora wpisu
liczby plusów
liczby odpowiedzi
Zadanie 8.2: ciągłość procesu (2 pkt)¶
Zadbaj o ciągłość pobierania danych:
ustal odpowiedni interwał pojawiania się nowych danych
użyj mechanizmu celery-beat by stworzyć mechanizm harmonogramowania tasków, który umożliwi pobieranie nowych wpisów
Zadanie 8.3: monitoring (5 pkt)¶
Dodaj możliwość monitorowania procesu pobierania danych:
dodaj do docker-compose instancję bazy danych, np. Prometheus lub InfluxDB
dodaj do docker-compose instancję Grafany (materiały z PDIOW)
alternatywnie do w/w, możesz użyć wersji chmurowej Grafany
zadbaj o zbieranie statystyk ze skryptu pobierającego dane. Przykłady zapisu danych w Prometheusie i Influxie
stwórz odpowiednie dashboardy ilustrujące proces zbierania danych. Stwórz co najmniej wykresy:
średniego czasu pobierania danych
ilości pobranych danych w czasie
histogram liczby plusów i odpowiedzi